We recently posted a quick introduction to SVMs for Scientists and Engineers, and this led to a question on Reddit. The user asked a more fundamental question than the one we were trying to answer. They asked (basically):
All this is well and good, but how do I know whether my problem is appropriate for use with an SVM? I’m doing object tracking – is that an SVM-like problem?”
This question is extremely deep and subtle, and it comes up a lot. Let’s break it down into some related sub-questions:
- What do we mean when we talk about “SVMs” or RVMs, or random forests, neural networks, or other ‘supervised learning’ approaches? And what types of problems are these intended to solve?
- Is my problem one of those problems? (or, “What kind of problem is my problem?”)
- Is that all “machine learning” is? What other kinds of problems are there?
As we mentioned, these questions may only admit rather theoretical-sounding answers, but we’ll try and give a quick overview in easy-to-understand language.
Supervised Learning – The Framework
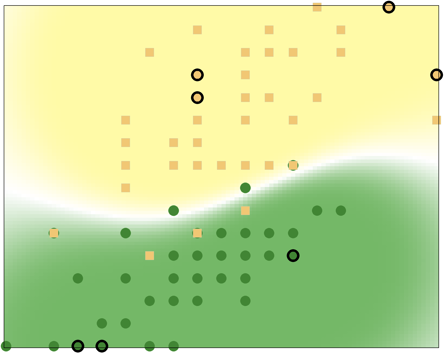
So, what are we talking about when we talk about ‘machine learning’? 90% of the time, when someone is talking about machine learning, or pattern recognition, or statistical inference they’re really referring to a set of problems that can be boiled down to a label-prediction problem.
Assume we have a number of objects, and a number of different measurements we collect for each object. Let’s use i to index the objects (1 through N) and j to index the measurements, (1 through P). Then the j’th measurement for object i is just x{i,j}.
Let’s use a simple example to cement ideas (this example is stolen from Duda, Hart, and Stork). Pretend that we’re running a fish-processing plant, and we want to automatically distinguish between salmon and tuna as they come down our conveyor belt. I don’t know anything about fish, but we might consider measuring something about each fish, like it’s size, weight, and color, as it comes doen the belt, and we’d like to make an automatic decision based on that information. In that case, x{3,2} might represent, say, the weight (in lbs.) of the 3rd fish. Similarly x{4,2} is the weight of the fourth fish, and x{1,1} is the size of the first fish. We can use x{i} to represent all the measurements of the i’th fish.
Note that if we assume each x{i} is a 1xP vector, we can form a matrix, X, out of all N of the x{i}’s. X will be size N x P.
So, for each fish, we have x{i}, and in addition to that information, we’ve also collected a bunch of ‘labeled examples’ where we also have y{i}. Each y{i} provides the label of the corresponding x{i}, e.g., y{i} is either ‘tuna’, or ‘salmon’ if x{i} was measured from a tuna or a salmon – y{i} is the value we’re trying to decipher from x{i}. Usually we can use different integers to mean different classes – so y{i} = 0 might indicate tuna, while y{i} = 1 means salmon. Note that we can form a vector, Y, of all N y{i}’s. Y will be size N x 1.
Now, if we’re clever, we’re going to have a lot of labeled examples to get started – this set is called our training set – {X,Y} = { x{i},y{i} } for i = 1…N.
The goal of supervised learning is to develop techniques for predicting y’s based on x’s. E.g., given then training set, {X,Y}, we’d like to develop a function, f:
(guess) y{i} = f(x{i})
That’s it. That’s supervised learning. Maybe this problem sounds super simple the way we’ve described it here. I assure you, the general problem is quite complicated, subtle, and interesting. But the basic outline is always the same – you have a training set of data and labels: {X,Y} and want to learn how to guess y’s given x’s.
A Little Nomenclature
- Number of Observations – the number of unique objects (fish) measured (N)
- Dimensionality – the number of measurements taken for each object (P)
- Feature – any column of X, e.g., all the ‘weight’ measurements.
- Label – the value of Y, and the value we want to infer from X
- Observation – any row of X, e.g., all the measurements for object i
Supervised Learning: Special Cases
Supervised learning is very well studied, and we can divide it up into a number of special cases.
Classification
If the set of Y’s you want to guess form a discrete set, e.g., {Tuna, Salmon}, or {Sick, Healthy}, or {Titanium, Aluminum, Tungsten}, you have what’s called a classification problem, and your y{i} values are usually some subset of the integers. More on wikipedia..
Regression
If the set of Y’s you want to guess form a continuous set, e.g., you have x{i} values and y{i} correspond to some other object measurement – say, height, or weight, you have what’s called a regression problem, and your y{i} values are usually some subset of the reals. More on wikipedia.
Multi-Task Learning
If you have a number of sets of data {X,Y}{k}, where each classification problem is similar, but not the same, (say in a nearby plant, you want to tell swordfish from hallibut) and you want to leverage things you learned in Plant 1 to help in plant K, you may have a multi-task learning problem. More on wikipedia.
Multiple-Instance Learning
If you only have labels for sets of observations (and not for individual observations), you probably have a multiple-instance problem. More on wikipedia.
Different Kinds of X data
Above we made the explicit assumption that each of the observations you made could be sorted into meaningful vectors of length P, and concatenated to form X, where each column of X corresponds to a unique measurement. That’s not always the case. For example, you might have measured:
- Time-series
- Written text
- Tweets
- ‘Likes’
- Images
- Radar data
- MRI data
- Etc.
Under these scenarios, you need to perform specialized application-specific processing to extract the features that make supervised learning tractable. More on wikipedia.
Why the PRT?
Now that you know a little about supervised learning, some of the design decisions in the PRT might make a little more sense. For example, in prtDataSetStandard we always use a matrix to store your data, X. That’s because in standard supervised learning problems, X can always be stored as a matrix! Similarly, your labels, Y, is a vector of size Nx1, as should be clear from the discussion above.
Also, prtDataSetClass, and prtDataSetRegress make a separation between the classification and regression problems outlined above.
Furthermore, the PRT makes it easy to swap in and out any techniques that fall under the rubrik of supervised learning – since algorithms that are appropriate for one task may be completely inadequate for another.
Is my problem a ‘supervised learning problem’?
It depends. Maybe? That’s kind of up to you. A whole lot of problems are close to supervised learning problems. Even if your specific problem isn’t exactly supervised learning, most really interesting statistical problems use supervised learning somewhere inside them, so learning some supervised learning is pretty much always a good idea. If you’re not sure if your problem is ‘supervised learning’, maybe an explicit list of other kinds of problems might help…
What other kinds of problems are there?
There are lots and lots of problems out there. Your problem might be much closer to one of them than it is to classic supervised learning. If so, you should explore the literature in that specific sub-field, and see what techniques you can leverage there. But if your problem is far removed from supervised learning, the PRT may not be the right tool for the job – in fact, your problem may require it’s own set of tools and techniques, and maybe it’s time for you to write a new toolbox!
Here are a few examples of problems that don’t fit cleanly into classic supervised learning although they may make use of supervised learning.
- System Control
- Reinforcement Learning
- Natural language processing
- Network prediction / Matrix completion
- Computer vision
- Video Tracking
And here’s a great paper, from 2007, that’s still quite relevant: Structured Machine Learning: 10 Problems for the Next 10 Years.
Conclusion
We hope this makes at least some of what we mean by “supervised learning” make a little more sense – when it’s appropriate, when it’s not, and whether your problem fits into it.
If your problem is a supervised learning problem, we hope you’ll consider the PRT!