Getting Started Examples
This document provides some examples of how to use the PRT to jump right in to developing data sets and performing classification.
Contents
Data Generation: prtDataSets
Let's get started by generating and visualizing data in MATLAB. All data that the PRT can utilize is stored in MATLAB objects called prtDataSets. When we call any function that starts with prtDataGen... the output will be a prtDataSet of some sort. To get started, clear your workspace, and close all MATLAB figures:
clear all; close all; format compact; clc; dataSet = prtDataGenUnimodal; %Generate uni-modal data under two hypotheses whos('dataSet');
Name Size Bytes Class Attributes dataSet 1x1 11414 prtDataSetClass
The output above tells us that the string 'dataSet' represents a variable in the MATLAB workspace, which is of type prtDataSetClass, and it takes up about 10000 bytes of memory. But what can we do with this dataSet variable? We can take a look at the public properties of the dataSet variable by using the disp() function, or by failing to end any MATLAB statement with a semicolon.
disp(dataSet)
prtDataSetClass
Properties:
nFeatures: 2
featureInfo: []
data: [400x2 double]
targets: [400x1 double]
nObservations: 400
nTargetDimensions: 1
isLabeled: 1
observationInfo: []
name: 'prtDataGenUnimodal'
description: ''
userData: [1x1 struct]
nClasses: 2
uniqueClasses: [2x1 double]
nObservationsByClass: [2x1 double]
classNames: {2x1 cell}
isUnary: 0
isBinary: 1
isMary: 0
isZeroOne: 1
hasUnlabeled: 0
This output shows us all of the public fields that dataSet has by virtue of being a prtDataSetClass. You can see fields like nClasses, which represents the number of unique object types represented in this data set, nObservations, and nFeatures. We won't go into too much detail here about the prtDataSetClass properties, but let's take a look at the methods that are available for processing prtDataSetClass:
methods(dataSet)
Methods for class prtDataSetClass: bootstrap plotAsTimeSeries bootstrapByClass plotBeeSwarm catClasses plotDensity catFeatures plotFeatureDensity catObservations plotPairs catTargets plotStar classNamesToClassInd plotStarIndividual explore prtDataSetClass exploreSimple removeClasses getBinaryTargetsAsZeroOne removeClassesByInd getClassNames removeFeatures getClassNamesByClassInd removeLabeled getData removeObservations getDataByClass removeTargets getDataByClassInd removeUnlabeled getDataUnlabeled retainClasses getFeatureInfo retainClassesByInd getFeatureNames retainFeatures getFeatures retainLabeled getKFoldKeys retainObservations getNumFeatures retainTargets getNumObservations retainUnlabeled getNumTargetDimensions select getObservationInfo setClassNames getObservationNames setData getObservations setFeatureInfo getObservationsByClass setFeatureNames getObservationsByClassInd setFeatures getObservationsUnlabeled setObservationInfo getTargetNames setObservationNames getTargets setObservations getTargetsAsBinaryMatrix setObservationsAndTargets getTargetsClassInd setTargetNames getUniqueClasses setTargets getX setX getXY setXY getY setY numClasses summarize permuteFeatures plot Static methods: loadobj
There are a lot of methods there, and most have pretty self-explanatory names; we'll get to most of them eventually. For now, all that's important to know is that prtDataSetClass objects are primarily responsible for storing and keeping track of two pieces of information for the user - the observations and targets. In most applications, the observations will constitute a nObservations x nFeatures matrix of doubles, and similarly, targets will be a nObservations x 1 vector of target labels. These fields of the prtDataSetClass are private, but they can be accessed using getObservations (equivalently getX) or getTargets (equivalently getY):
myObs = dataSet.getObservations; whos('myObs'); myTargets = dataSet.getTargets; whos('myTargets');
Name Size Bytes Class Attributes myObs 400x2 6400 double Name Size Bytes Class Attributes myTargets 400x1 3200 double
Visualization
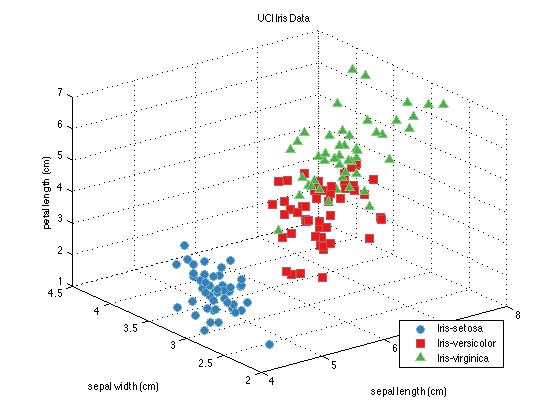
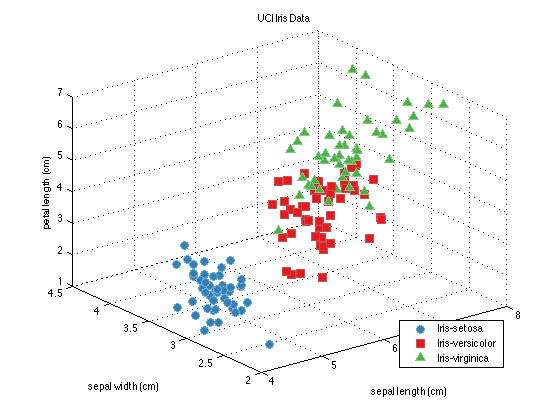
Visualization of data is a fundamental part of data exploration and understanding. The PRT's data set classes provide interfaces to make visualization easy and intuitive. Let's start off by loading a different data set - this one is the famous Iris data set, with data collected for telling the difference between 3 classes of flowers. For now, we'll use the retainFeatures method of the prtDataSetClass class to reduce the dimensionality of the data from 4 to 3 for visualization:
dataSet = prtDataGenIris;
dataSet = dataSet.retainFeatures(1:3);
plot(dataSet); % See note below
A Little Object Oriented Programming
Those last commands make the plot you can see directly above. Note what happened here - the prtDataSet dataSet knows what the name of the data set is, and uses that as the title of the figure. It knows the names of the classes of flowers the data was collected on, and uses those in the legend. And if the data set knew the names of the features, it would have used those on the axes labels.
Note: For those of you familiar with MATLAB, but not with object oriented (OO) programming, you probably recognize the plot() command above, but are used to seeing it called more like so: x = 1:10; h = plot(x,x.^2,'b'); So, how did we call plot on the dataSet object? That's a factor of object oriented programming, and we cover a little of that later in this book, but if you want to know more, the MATLAB website has a good reference on how OO programming works. For now, just trust us - you can call plot(dataSet), and MATLAB knows what to do.
More Visualization (plotPairs)
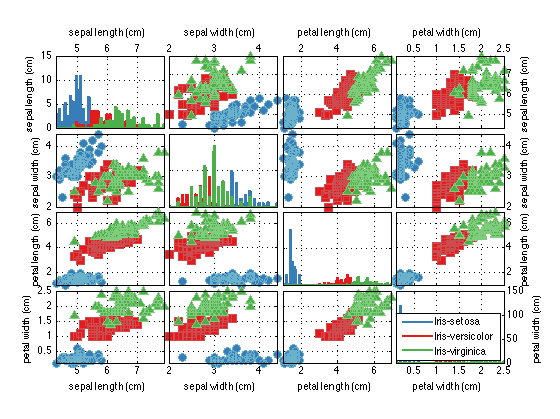
When we wanted to plot the data in the Iris data set, we had to artificially reduce the dimensionality of the data using retainFeatures. That's because the prtDataSetClass plot command doesn't work for data sets with > 3 dimensions. However there are a number of alternative approaches to data visualization that are applicable in higher dimensions. Let's take a look at a few below. We'll start with plotPairs:
dataSet = prtDataGenIris; %4-dimensional data
dataSet.plotPairs;
More Visualization (plotStar)
As you can see, the plotPairs method of the prtDataGenIris enables us to visualize higher dimensional data by plotting all of the pair-wise combinations of the features in a grid. The diagonal elements of the plots show ksdensity estimates of the relative density of each feature in isolation, while the off-diagonal images show pair-wise scatter matrices. Pair-wise plotting can be slow for very high dimensional data.
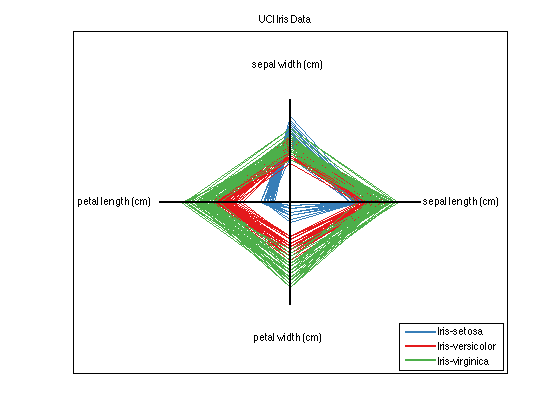
Up next is a technique that plots each observation as a shape with nFeatures vertices (in this case since dataSet has four feature dimensions, the resulting shapes are quadrilaterals). This technique illustrates the differences between high dimensional data in a simple and easy to understand way.
close all;
dataSet.plotStar;
Explore
Finally, the explore method of the prtDataSets enables interactive visualization of different dimensions of the data sets using GUI controls. You can start the explore GUI using the command below, and you'll be greeted by the GUI Figure below.
explore(dataSet);
Data Processing
Now that we've explored some of the techniques available to visualize data, let's apply some transformations to the data. To do this, we need to know a little bit about prtActions. Most everything you can do to data in the PRT - alorithms/classifires/regressors in the PRT are implemented as prtActions.
For now, all that's important to know is that prtActions have two important methods - "train" and "run". The train method accepts one prtDataSet and outputs an object of the same class as the prtAction being used. The "run" method, in contrast, accepts a prtDataSet input and outputs another prtDataSet with data changed to reflect the action undertaken. For example:
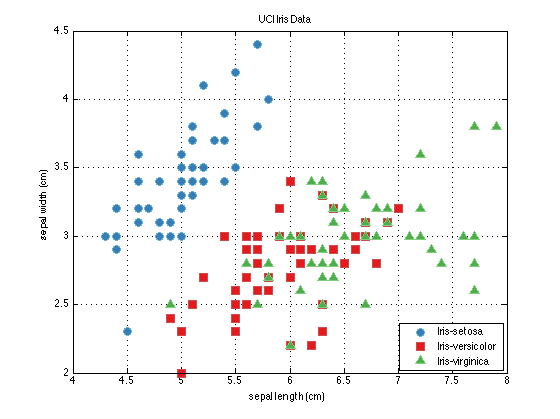
close all; % Generate a data set and a PCA pre-processing function: dataSet = prtDataGenIris; dataSet = dataSet.retainFeatures(1:3); %retain the first 3 dimensions of the Iris data myPca = prtPreProcPca; myPca.nComponents = 2; %I'd like to use the first 2 principal components % Train the PCA to learn the principal components of the data: myPca = myPca.train(dataSet); dsPca = myPca.run(dataSet); %Run the PCA analysis on the data % plot the data. figure(1); plot(dataSet); figure(2); plot(dsPca);
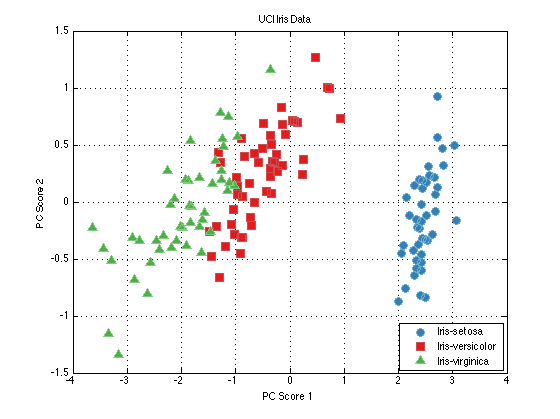
Building a Classifier
Let's continue processing our new data set in PCA space. Let's say we'd like to generate a classifier that can tell the difference between the types of flowers in the Iris data set. Since the Iris data set has multiple classes (types of flowers, you can tell this is the case since dataSet.nClasses > 2), we need to use a classifier that can handle multiple hypothesis data. KNN classification algorithms are a decent choice in this case. Let's build and visualize a KNN classifier on the 3-PC projected Iris data.
knnClassifier = prtClassKnn; knnClassifier = knnClassifier.train(dsPca); plot(knnClassifier)
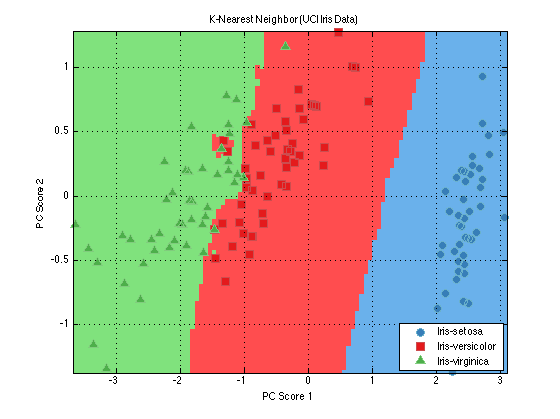
The plot command shows the results of classification for each hypothesis in one 2-D axes. Red regions of the axes correspond to regions where the classification algorithm's most likely guess is "Iris-versicolor", and similarly for blue regions (Iris-setosa) and green (Iris-virginica).
Evaluating the Classifier
Now that we have a classifier, and are comfortable with the decision boundaries, we can evaluate our classifier. Let's use k-folds cross-validation to see how well our classifier would perform in a realistic test scenario.
truth = dsPca.getTargets; %the true class labels yOutKfolds = knnClassifier.kfolds(dsPca,10); %10-Fold cross-validation %We need to parse the output of the KNN classifier to turn vote counts into %class guesses - for each observation, our guess is the column with the %most votes! [nVotes,guess] = max(yOutKfolds.getObservations,[],2); subplot(1,1,1); %don't plot in the last figure window. prtScoreConfusionMatrix(guess,truth,dsPca.uniqueClasses,dsPca.getClassNames); title('Iris Classification Confusion Matrix');
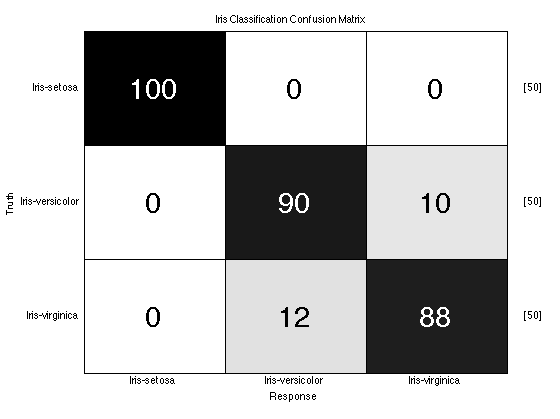
One More Thing...
Above, we had to do a bunch of work after we ran our classification to turn the outputs of a classification algorithm into a set of decisions. Luckily, the PRT provides some utilities to automatically do this for you, including one object prtDecisionMap, which performs maximum a-posteriori decision making.
But now, you might be thinking "Wait, I have to keep track of a PCA object, a KNN object, and a MAP Decision object all at once, and make sure to run K-folds at the right places? What if I wanted to include PCA in the k-folds cross validation, and not worry about running the MAP after everything else?"
The PRT has a solution for you. Basically, you'd like to be able to string together a set of prtActions into one long action that you can treat as one entity. The PRT has overloaded the MATLAB operator "+" to do this for you. So, you can write:
myAlgo = prtPreProcPca + prtClassKnn;
To string together PCA and KNN into one object (we refer to combinations of prtActions like this as "algorithms", since they are implemented in a M-file called prtAlgorithm, which you actually never have to call). Let's see how this affects our development from our last set of code:
dsIris = prtDataGenIris; algo = prtPreProcPca('nComponents',2) + prtClassKnn + prtDecisionMap; plot(algo); %Note: this plots a block diagram of the algorithm!
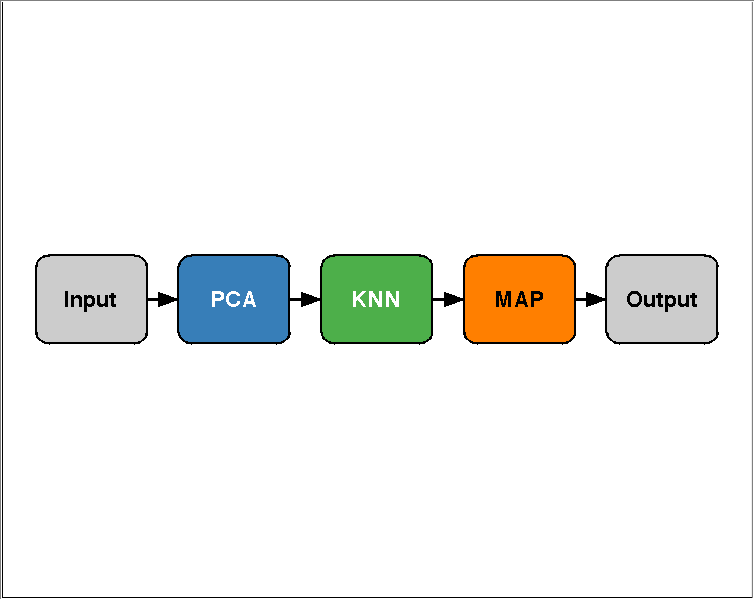
Now, running the algorithm and scoring it is very simple:
close all; yOutAlgoKfolds = algo.kfolds(dsIris,10); prtScoreConfusionMatrix(yOutAlgoKfolds,dsIris); title('Iris Classification Confusion Matrix'); % These results show pretty good performance for separating Iris-setosa % from the other two classes, and less separation between versicolor and % virginica (your results may vary depending on the random folds chosen in % kfolds.
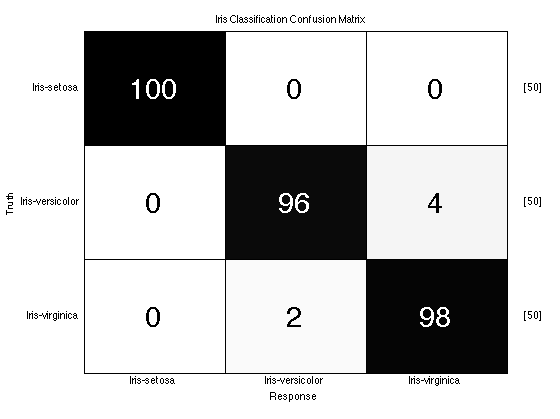
Data Generation: Using Your Own Data
In many cases, you will already have some data you've collected that you'd like to work with in the PRT. If the data is a classification data set (i.e. each observation has a corresponding class label - "target"/"non-target", or "type 1"/"type 2"/"type 3") it's easy to make a prtDataSetClass object from your data.
To get started using your data, you'll need to have your data stored in two matrices. Your observations should be in a matrix of size nObservations x nFeatures, and class labels should be in a vector of size nObservations x 1. Each element of the class labels vector should correspond to a class index. For binary classification problems, y should take values 0 and 1. For M-ary classification problems, and set of M unique values will work.
For example, the following code generates a prtDataSetClass using raw data in matrices x and y:
nSamplesPerClass = 100; nFeatures = 2; mean_0 = 0; mean_1 = 2; x_0 = randn(nSamplesPerClass,nFeatures) + mean_0; y_0 = zeros(nSamplesPerClass,1); x_1 = randn(nSamplesPerClass,nFeatures) + mean_1; y_1 = ones(nSamplesPerClass,1); x = cat(1,x_0,x_1); y = cat(1,y_0,y_1); dataSet = prtDataSetClass(x,y); plot(dataSet);
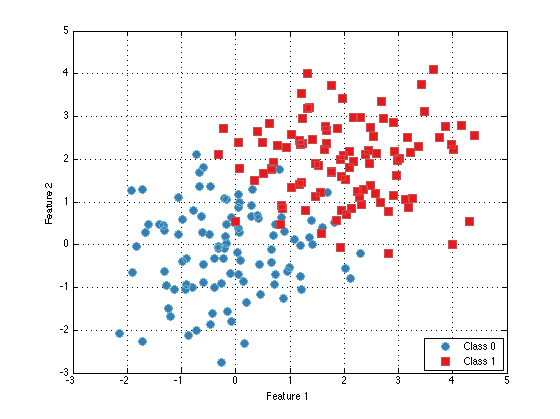
At this point you're pretty ready to start playing with the PRT. Definitely check out the rest of the documentation, which is small, but growing. If you have any questions about a specific M-file, make sure to check the M-file's help entry with "help MFILE" or "prtDoc MFILE".